논문 작성을 위해 고민하기
최근 나갔던 MWP 대회 및 공부했던 내용을 토대로 한국어 수학 문장제 풀이에 대한 짧은 논문을 써보기로 하였다. 다만, 여태껏 했던 실험 내용과 마지막 대회 제출 내용이 상이한 점과 기록들에 대한 손실로 인해 논문을 쓰기 위해 제대로 정리하는 시간이 필요했다. 평소에 문제해결에만 집중하여 정리를 잘 안하곤 했었기에 지금과 같은 상황을 비일비재하게 맞이했고, 그때마다 꽤나 힘들었던 기억이 많았다.
그래서, 5단계 문제 해결 과정을 조금 도입해서 현재에 대한 정확한 분석과 동시에 문제 해결에 대한 모든 이력을 남기고자 블로그에 글을 작성한다. 우선 문제 해결법을 인터넷에서 검색하여 적당한 방법론 (사실 그래봤자 거의 대부분이 비슷한 방법을 표방하고 있었다.)을 가져왔다.
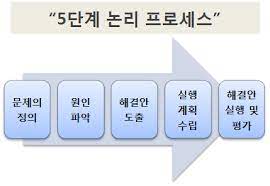 http://www.tnfleaders.com/education/process.php
http://www.tnfleaders.com/education/process.php
이미지 출처 캡션이랑 크기조절 하다가 시간 좀 쏟기는 것 같아서 그냥 때려쳤다.
하여튼, 내가 생각했던 문제 해결 능력을 기르기 위해 찾았던 문제 해결 과정이었으나, 문제 해결을 한다는 점에서 “논문쓰기” 와 같이 추상적이고 넓은 범주의 문제는 이 방법으로 해결할 수 없었다. 논문을 쓰다가 어떤 문제, 예를 들어 레퍼런스의 작성법을 모르겠다, 혹은 참고 문헌에 대한 선택이 필요하다 라는 작은 범주의 문제에서는 이전과 같은 프로세스에서의 문제 해결이 가능하다.
하지만 문제의 정의 및 현재 진행 상황 복기는 해야할 부분인 것 같다.
진행이력 복기.
- (210712) genBert 깃레포따라서 데이터 생성 및 데이터 분석 - 논문에서 사용하는 방법론 취득
- (210715) mathQA 데이터의 linear_formula를 tgt로 한 openNMT 학습.영어 자체에서 99%의 성능 / pororo를 사용한 한글 번역. 18시간이나 걸렸음.
- (210719) 한국어로 번역한 mathQA 데이터의 학습 결과, val단계에서 91%가 나왔음. (tgt는 linear_formula 동일, 번역x) / asdiv를 openNMT로 학습한 결과 38%의 성능이 나왔음. - tgt vocab에서 일관되지 않게 생성됨. (개별 digit에 대해 tgt 매겨짐. mathqa는 n0,n1같은 entity)
- (210722) asdiv, mathQA 논문분석 - mathQA 연산자 코딩에 한계점 봉착 / drop 번역본 kobert finetuning 시도(MTMSN 관련)
- (210726) drop kobert fintuning 난항. / SNI (Significant Number Identification) to mathQA - 문제에 나타나는 수를 모두 SNI로 치환하는 작업 진행. 그 후 OpenNMT로 예측된 equation을 풀어봄. equation은 직접 정의(함수)하였음.
- (210729) 번역된 mathQA를 SNI로 치환해 학습. - okt를 사용하여 띄워쓰기 조정함으로 숫자를 정확히 나눔. 번역과정에서 argument 사라지는 문제는 제외하여 eqauation 정답률,eqauation 풀이 정답률이 각각 25%, 18% 정도가 나왔음. / graph2Tree 한글버전 진행을 위한 품사 태깅진행. - ner 라이브러리 kkma, mecab 등을 확인하여 적용 가능성 판단 / MTMSN drop 한글번역본 학습 - loss가 급격히 튐. 번역이 난해하거나 tokenizer 문제로 예상.
- (210802) graph2tree를 pororo ner로 분류. (kkma, mecab)은 ner pre-trained 모델이 없기에 사용 불가 판단. 하지만 pororo ner output attention map을 시각화하여 확인한 결과 각 entity가 다른 entity에 갖는 dependency는 확인되지 않음. / 한글실험은 두고 영어 MTMSN 실험. - 바로 발산. / korQuad 데이터 확인.
- (210809) MTMSN 여전히 오류 발생 / genBert를 kobert로 바꾸어 시도. genBert 레포의 ND 데이터 생성 부분을 한국어 버전에 맞게 수정. - tokenizer 수정. TD 부분 한국어 스크립트가 필요함을 깨달음.
- (210823) ND에 대한 데이터는 안정적으로 생성되었음. mlm 데이터를 aihub쪽 한글 데이터를 가져와 구축. TD는 보류. / 대회 문제 분석 시작.
- (210830) genBert 한글버전에서 사용한 tokenizer가 제대로 되지 않았음(BPE 미지원) - 새 tokenizer 도입 / Bert enc + Tree decoder 사용성 검토
- (210902) SAU-solver 분석
- (210906) 삽질…
- (210910) 문제 정의서 분석 / genBert mlm+nd 학습 완료 평가 지표 확인. 자체 평가 acc 지표는 높았으나 inference 출력이 깨짐. - 추상적으론, mlm 데이터가 numerical reasoning에 있어 좋은 효과를 주지 못했을 것이란 판단(전체적으로 비효율적인 학습) / SAU-solver에 맞도록 문제 생성 template 작성완료. (entity 및 number가 다양할 수 있도록)
- (210923) genBert 학습 결과가 완전하지 못함 / 생성한 template 문제에 대한 SAU-solver 테스트 결과 loss가 떨어지지 않음.
- (210927) 데이터 구축팀에서 받은 약 250개의 번역데이터를 genBert로 학습. overfitting이 나타남. / genBert의 출력을 python code로 나타낼 수 있는 방법 고찰.
- (210930) openNMT, SAU-solver, genBert 모델의 각 기능 및 도출 결과식을 비교. - genBert는 annotated formula를 예측하도록 수정..? / 데이터 중 python 문법 코드를 예측하는 방법..?
- (211004) SAU-solver의 tokenizer 구성이 학습데이터를 통해 이루어짐. - 학습데이터에서 나타나지 않은 token은 oov 문제를 일으킴. / 그래서, genBert의 encoder 부분을 동일하게 하여 SAU-solver와 조립을 도모.
- (211007) electra 모델과 SAU-solver의 decoder를 연결하는데 성공함. - loss는 떨어지지만, 제대로 예측이 안되는 문제를 확인. 모델의 특성 이해 후 편집 진행.
- (211011) 학습 데이터가 제대로 되어 있지 않은 점 확인 (토큰 위치 상이함) - 모델 분석 더 진행 / 서수(일,이,다섯 등)에 대한 문제점 파악 및 치환(숫자로) 작업 진행 - 문제 생성 템플릿 그에 맞게 수정
- (211014) 생성한 템플릿으로 많은 데이터 생성. 학습 정상 진행 확인.
- (211018) 정상적으로 eqaution이 학습이 되는 모습을 확인하였음. / python code generator 작성 완료.
ㅋㅋ,, 삽질하고 아무것도 못건져간다고 생각하려니 참 마음이 씁쓸했다. 하지만 중간중간 웹 작업이 끼여있었고, 내 스스로도 그렇게 부지런하지는 못했기에 3개월의 기록이 얼마안되는 것처럼 느껴진다. 뭐랄까 너무 중구난방이라는 느낌이 강한 것 같다.
우선 진행했던 내용들을 토대로 큰틀에서의 맥락을 잡을 수 있을 것 같다. 사실 이렇게 정리할 수 있었던 것도 교수님께 보여드릴 ppt를 매번 만들어갔고, 그것들이 흔적으로 남았기 때문이다. 기록으로 남기는 것이 중요하다는 것을 다시 상기시킬 수 있는 정리작업이었다…